[The following is a guest post from data scientist and Eurovision super fan Sean Nixon. – Ed]
Every year, the constituent countries of the European Broadcasting Union (EBU) send their finest bands, divas, baking grandmas, and yodelers, to compete in the Eurovision Song Contest. Two Semi-Finals cull more than forty competing acts down to 26 who will perform at the Grand Final: ten countries from each of the two semi’s, the Big Five (France, Germany, Italy, Spain, and the United Kingdom) plus the hosting country. Beginning in 1975, the voting structure for the ESC was finalized to a ballot awarding 1–8, 10 and 12 points with each competing country (including those that only competed in the semi-finals) submitting a ballot (no voting for yourself). It has since become a hobby amongst european academics to dig through the eurovision voting records for network structures, economic correlations, or voting cartels. Last year, Overthinking It joined in on the data analysis fun, and from those humble first attempts has come the Eurovision Voting Examiner (EVE). You can try out EVE here.
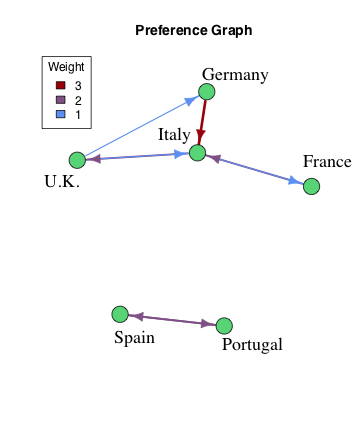 As an illustrative example for how the EVE system works under the hood, consider a mini-Eurovision consisting of just the Big Five and Portugal (the host country for 2018) along with a predetermined set of preferences for who they’d vote for if song quality weren’t a factor. This is modeled by a graph where the green nodes represent the countries and the blue arrows (edges) represent a voting preference. For example, Spain and Portugal form a vote exchanging pair while Germany has an unrequited love for Italy. Each edge between the countries has a weight that determines how much this preference effects the voting. Note that this graph break up into two disjoint Voting Blocs (communities in Graph Theory terms), one with Spain and Portugal and containing the U.K., Germany, Italy and France. The ultimate goal is to reproduce this graph from voting data and reconstruct these two voting blocs.
As an illustrative example for how the EVE system works under the hood, consider a mini-Eurovision consisting of just the Big Five and Portugal (the host country for 2018) along with a predetermined set of preferences for who they’d vote for if song quality weren’t a factor. This is modeled by a graph where the green nodes represent the countries and the blue arrows (edges) represent a voting preference. For example, Spain and Portugal form a vote exchanging pair while Germany has an unrequited love for Italy. Each edge between the countries has a weight that determines how much this preference effects the voting. Note that this graph break up into two disjoint Voting Blocs (communities in Graph Theory terms), one with Spain and Portugal and containing the U.K., Germany, Italy and France. The ultimate goal is to reproduce this graph from voting data and reconstruct these two voting blocs.
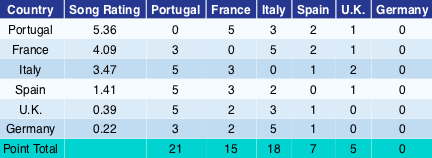
Table 1
To simulate a contest and generate voting data, the song for each country is randomly assigned a rating. For each county, the weights from the Preference Graph are added to the song ratings and a ballot awarding 1, 2, 3 and 5 points is generated based on these modified ratings. (Technical Note: Ratings are chosen from a normal distribution with standard deviation 2 so the weights in the Preference graph range from 0.5–1.5 standard deviations.) For the simulation shown in Table 1, this means that Italy manages to secure a second place finish over the higher rated song from France. Specifically, Germany has a preference for Italy with weight 2. When this is added to Italy’s 3.47 song rating we get 5.47, which is enough to earn Italy 5 points from Germany.
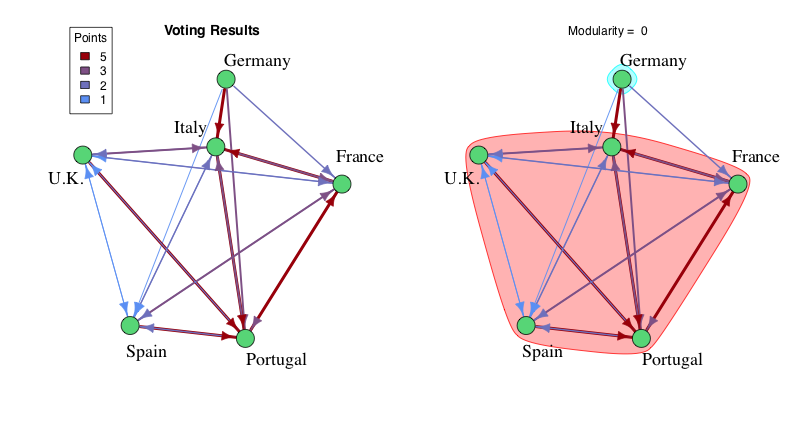
All the votes can be interpreted as the edges in a new graph connecting the original country nodes, i.e., Portugal giving France 5 points becomes an edge from Portugal to France with weight of 5. We can try to reconstruct the original communities from the Preference Graph by grouping the countries in a way that maximizes the Modularity. In layman’s terms, modularity measures how well the edges of a graph manage to stay within the voting blocs. The more edges that connect two countries within the same bloc the better. A formal definition might look like:
Modularity = |
Actual # of Edges within the Blocs – Expected # of Edges within the BlocsTotal # of Edges |
This means that you need to beat expectations to have a positive modularity. For example, putting all the countries into a single bloc yields a modularity of zero, since you already expect expect all the edges to stay within that one Mega-Bloc. A negative modularity means that you’ve done a terrible job of picking the voting blocs.
Trying to find the original voting blocs directly from the graph of voting results produces the correct answer in about one third of the simulations. The rest of the time, song quality skews the results, creating spurious connections in the direction of contest winners and missing connections to the weak entries. In the example from Table 1, the high rating (quality) of Portugal’s song, along with Germany’s abysmal rating, result in Germany being left out in the cold while the U.K., Italy, and France fall into the orbit of Portugal.
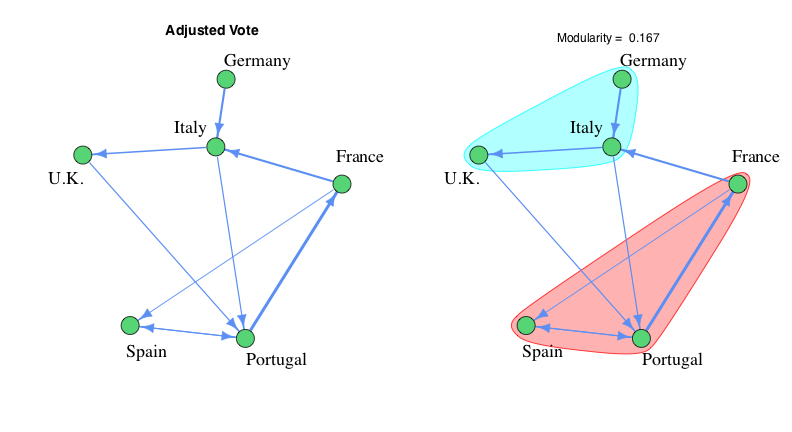
In an effort to remove the confounding effects of song quality, we introduce a new Adjusted Vote, which is equal to number of points awarded from a particular country minus the average number of points awarded across all countries. The edges of the Adjusted Vote graph represent all the places where a greater than average number of points were awarded. In this case, maximizing the modularity recovers the original voting blocs about two thirds of the time, doubling the success rate of just using the raw voting results. The example contest from Table 1, which you might have noticed was picked specifically for being difficult to analyze, shows a noticeable improvement after changing over to the Adjusted Vote. (Quite literally for the modularity value, which increases from 0 to 1.167.) The biggest error is the edge between Portugal and France that occurs because the U.K. and Germany snubbed France’s higher rated song in favor of Italy. Like when the sergeant asks for a volunteer and everyone but Bugs Bunny takes a step back. This is as far as the math will take us for a single competition. The final step is to take data from a series of simulations to smooth out the outliers of any particular contest.
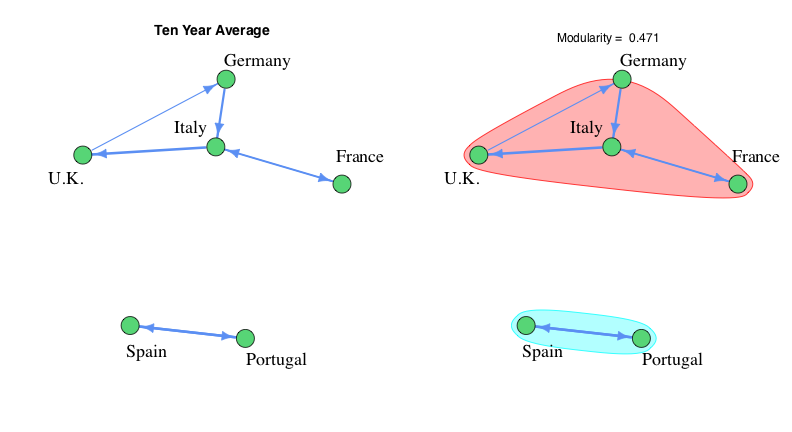
In the Ten Year Average graph, we simply take an average of the Adjusted Vote across ten simulated contests. The edges in this graph represent the top quartile of all the averages, which amounts to 7 out of the 30 possible edges. This ensures any negative or extremely tenuous connects are ignored. At this point, the method is robust to enough to see nearly 100% success in reconstructing the Voting Blocs from simulated contest data.
For the calculations that EVE performs we only take the top 10% of the averages. For the much larger data set that EVE works with, this is the sweet spot between keeping as much as possible while also limiting the computational requirements, allowing new graphs to be rendered in real time. The exact cut off does not cause a meaningful change in the resulting Voting Blocs, and at most sees the shifting around of free agents that don’t belong anywhere.
E.V.E. Highlights
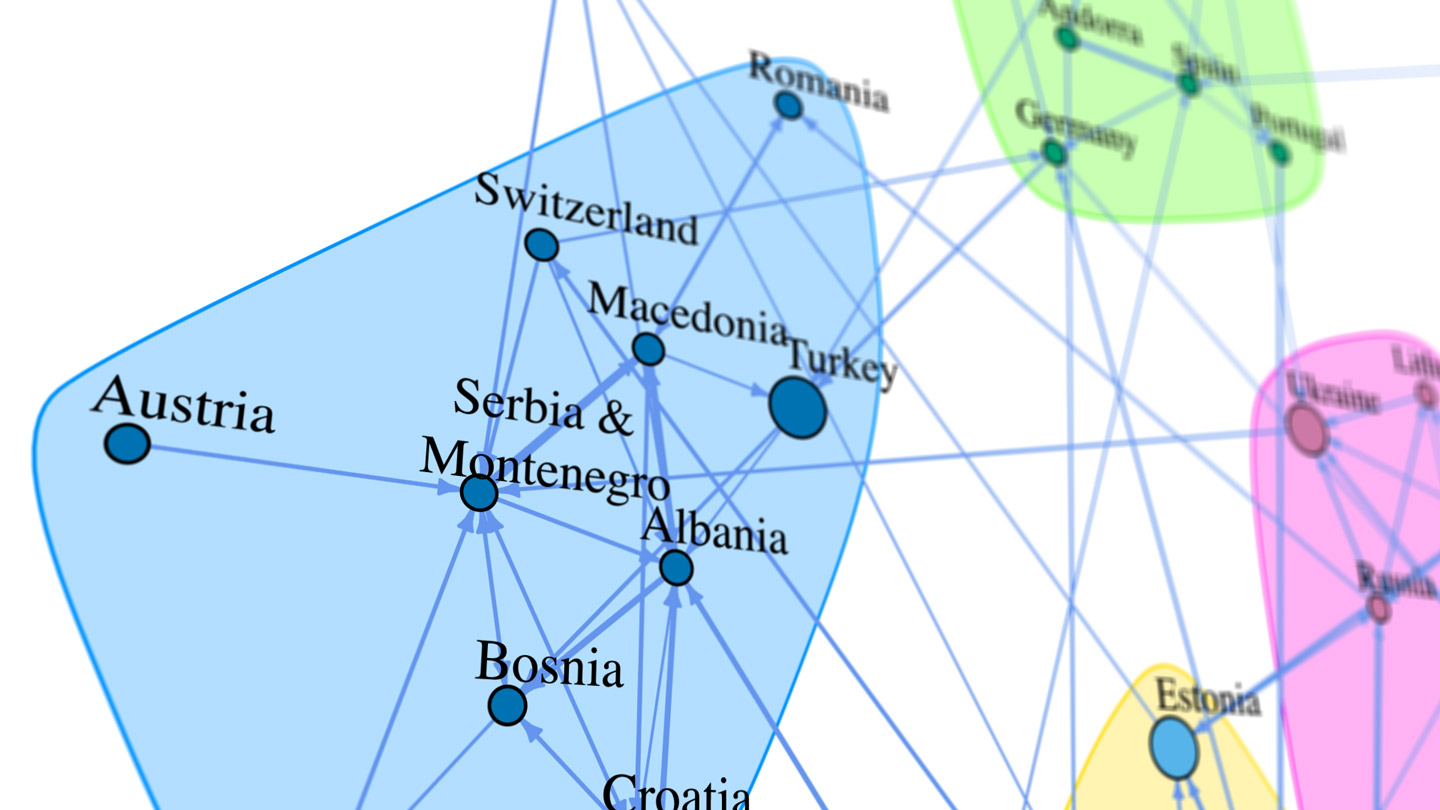
- After the breakup of Yugoslavia in 1993, it takes about ten years for a new voting bloc to form out of the six constituent republics (Bosnia, Croatia, Macedonia, Montenegro, Serbia, and Slovenia).
- In the Nordic voting bloc (Denmark, Finland, Iceland, Norway, and Sweden), Finland is the most likely to break rank.
- The biggest Eurovision BFFs are Romania and Moldova (Greece and Cyprus are number two). This makes a lot of sense, since modern Romania was formed from the merging of Wallachia and Moldovia in 1859. While the Soviet annexation of Moldova broke up that old alliance, the countries still share a common language, traditions, and taste in Euro-pop.
- Strained relations between the Ukraine and Russia in recent years have resulted in a steady downward trend in their previously strong Eurovision pairing. However, their mutual ties in the region ensure that they remain in the same voting bloc.
- The biggest discrepancy between points awarded vs points received exists between Turkey and Armenia.
Is there any mathematical link between Denmark and Australia? The crown princess of Denmark is Australian. I think Jess got the best judge vote for her of 10 points from them although she got smashed in the viewer votes.
Plus coincidentally as an Australian I have a beard worth stroking, Denmark style.
And while I put my 2 cents in, everyone should viewer vote for Australia. Don’t think about what’s the best song; think about where do you want to go for a holiday next year.
Wooooo!
Eurovision season has started again. Yesterday I was lucky enough to go to the Australian qualifiers.
If you haven’t seen it yet, to quote Australian music legend Molly Meldrum, do yourself a favour and check out Kate Miller Heidke’s Zero Gravity. It is the perfect combination of Dami Im’s ‘Just sing awesome’ and the general craziness of all things Eurovision.
Also my kids have been overthinking Eurovision and costumes. Looking at clips over the last couple of years, and the ten competitors in last night’s qualifiers, why do the performers rarely wear costumes that have colour in them? I would have thought that bright coloured costumes would be an easy way to stand out from the crowd but I would say over the last two years about 10-15% of performers are not in white, black or grey.
I wonder if this is a symptom of Eurovision’s dual nature of being both serious and completely crazy and everyone being aware of that. Does the decision to wear bright colours just instantly put you in the crazy box and so people don’t do it? In the same way if you have a song that has a gimmick, perhaps its easier to dress conventionally because you can say that it’s a serious song that happens to have a camel in it for some reason.
One day when I’m bored I will quantify costume colour vs Eurovision success. I could make a chart. I like charts.