
[Enjoy this guest post by Janette Rounds. – Ed.]
Recently, I binge-watched the first season of Arrow. I have to admit I was completely on board, in spite of the numerous, erroneous TV tropes regarding computer hacking, the inconsistent acting, and the formulaic plot. I was even willing to accept the whole earthquake machine thing. I was all in, right up until the scene in Episode 22, where the supposed hacker character (Felicity) says, “There’s at least a teraflop of data to go through.”

Oh no! Arrow, how could you? I have to stop watching the show now!
For those not in the know, a teraflop is a measurement of the rate of processing, specifically a trillion floating point operations per second. If Felicity had a normal computer, she should have said, “at least a terabyte of data to go through” because a terabyte is a measurement of an amount of data. How could she have an amount per second of data to go through?
I finished the season, and then decided to stop. I didn’t think much more about Arrow until weeks later, when I found myself thinking about the relationship between distance, velocity and acceleration. Distance is pretty self-explanatory, but units for velocity are usually put in terms of distance/time. Acceleration is even more interesting because the units are usually phrased in terms of distance/time2.
If you take total distance and divide it by the total time, you get average speed, or the average rate of change of distance. If you take total speed and divide it by the total time, you get average acceleration or average rate of change of speed. If you take total acceleration and divide it by time, you get jerk, a weird physics term that translates to rate of change of acceleration. You can go further with the averaging, but we don’t really need to. Interestingly, the derivative of position is speed, and the derivative of speed, or the second derivative of position is acceleration. The third derivative of position or the first derivative of acceleration is jerk.
Suddenly in the midst of this thought process, my brain switched back to Felicity and her poor addled brain mistaking bytes for flops. What would it mean if the flop/byte switch wasn’t a mistake? If we assume flops are equivalent to speed, then Felicity saying teraflops (speed) to go through (referencing future implies time) is like dividing speed by time. She is talking about the acceleration of her computing process. Instead of staying at a fixed speed, Felicity’s processor is changing as it computes, becoming faster (I hope). If we took the first derivative of Felicity’s processor speed, there is no telling what it would look like, except that the graph would not be a horizontal line.
Just a heads up: normal computers don’t work like that. If we took the first derivative of a normal processor’s speed, our answer would be 0 because the derivative of any constant number is 0. The graph would be a horizontal line at 0. If your processor runs at 10 gigaflops, it will always run at 10 gigaflops unless you break it. So, other than destruction, what could make your processor speed change?
The modern processor has a fixed number of flops it can manage, and we change processor speed generally by adding or subtracting microprocessors. Humans don’t make processors by hand. Instead they require massive clean rooms full of enormous machines and photochemical inscribing equipment. In Arrow, we see none of that. What could be making processors?
Since we don’t hear anyone on Arrow talking about moving black specks, we can assume that whatever is making processors is very small, so small that it operates at the molecular scale. Additionally, the scale that processors are constructed on would prevent anything much larger from building them without clean rooms and such like. These small things would have to be self-replicating machines; Felicity is not a millionaire (that we know of), and it would take a lot of money to build even one of these tiny machines. If you had to build multiple, it would require a significant chunk of Queen Consolidated’s total resources. If however, you only had to build the first one, and you could simply provide the materials and the rest built themselves, that might be possible for your typical IT person to manage. So we have these self-replicating tiny machines that are at work in Felicity’s computer. No, let’s call them what they are. Nanobots are making new nanobots to serve as processors so Felicity’s data processing can accelerate.
If Felicity has a hoard of nanobots, it would explain so much! Like how in a matter of days Felicity managed to pinpoint the water source being used to produce an entire city’s supply of an illegal drug. Also, how she managed to fit terabytes of data onto a Windows 8 tablet and hack into everything ever. It could also possibly explain how she managed to use Windows 8… like at all.
![[Sick IT burn. - Ed. Seriously, though, I'm baffled by Windows 8. - Ed.]](https://www.overthinkingit.com/wp-content/uploads/2014/03/windows8-590x310.jpg)
[Sick IT burn. – Ed. Seriously, though, I’m baffled by Windows 8. – Ed.]
To answer that question, we would need to know the amount of time involved. Felicity and Oliver break into Merlyn Global by using a burger delivery as cover, so we can reasonably assume that the hacking occurred around noon or one. We don’t know when Felicity makes her discovery of the location of the earthquake machine, but we do know it is “later that night”. Night implies sometime between 9 and midnight, so Felicity’s calculations probably ran between 8 and 12 hours. We also know that she accelerated her processing power by at least 1 teraflop. We don’t know what her starting processing power was but the fastest processor on the market today can hypothetically manage 0.125 teraflops (See Appendix). The best single core CPU can hypothetically manage 0.012 teraflops. I’m going to assume that each nanobot boosts processing power by half that. In other words, each nanobot boosts processing power by 0.006 teraflops. I’m also going to assume that the effect is additive rather than multiplicative. That results in a minimum nanobot population increase of 167 nanobots. If we assume those nanobots were built at a constant rate, we would have a range of 14 to 21 nanobots being produced per hour. However, we cannot assume a constant rate of nanobot construction. They are building themselves, remember. If we start with a relatively small number of bots, say 2, and grow our bot population to 169 (167+2), the rate of bot construction would depend heavily on the number of bots we could use for construction at any given time.
Applying the principles of population growth we have a graph that looks like this (see appendix for the formula and all that):
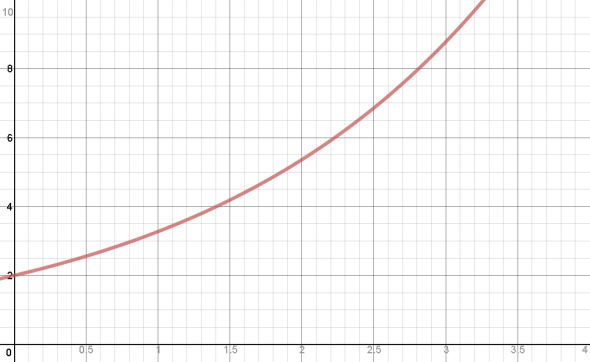
However, that is the graph for unrestricted growth. All populations face some kind of limiting factor eventually. In this case, the population would not be limited by resources, but by something called processor overhead. Processor overhead refers to a fixed limit of processor power due to things like transmission speed and the ability of the CPU controller to apportion tasks. We have to include a limit to nanobot production in our analysis. I am going to assume that if nanobots are possible, we’ve made some significant advances in CPU controllers and network transmission. A more realistic population graph looks like this:
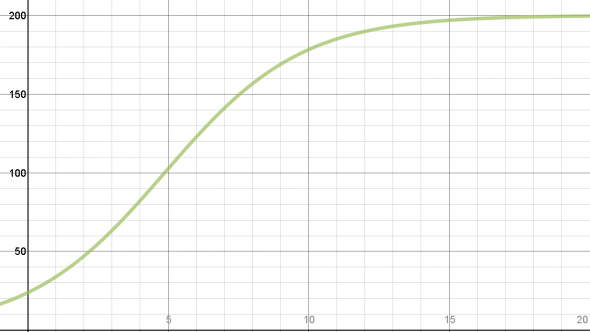
Now comes the difficult part. If we multiply the equation mapped out in the graph above by our 0.006 teraflops per second per bot, we have the maximum floating point operations per second for any given time. In order to find the total floating point operations performed, we need to take the integral of the equation of the graph. (If math is your thing, look in the Appendix to see how I did that!) Then we plug in 9 – 0 and get 817.3156 trillion floating point operations total.
There is no way to translate floating point operations into bytes of data. However, if we break down the phrase “floating point operation,” we can perhaps find an approximation that will satisfy. In modern computers, each “float” is number that takes up 4 bytes worth of data. Each floating point operation has at least 4 bytes for the floating point and some amount for the operation. Let’s assume that each operation takes 8 bytes of data. This is not a direct translation, as there is no way to predict what operations will take up an amount of data storage based on the limited data we have. Quit yelling, internet, I know. For the record, Felicity started it. We have to make these assumptions however, because Felicity isn’t saying anything.
So we take (4 + 8) and multiply that by our number of floating point operations and we get 9,808.2197 trillion bytes of data. That means 9,808.2197 terabytes of data, or 9.81 petabytes (a petabyte is equal to a quadrillion bytes). For reference, one of my current computers holds 1 terabyte of data. Facebook processes as much as 500 terabytes (0.5 petabytes) of data PER DAY. It would be entirely conceivable for a large company such as Merlyn Global Group to have 10 petabytes of proprietary data stored on internal servers.
Where does that leave us? We have Felicity, capable of building nanobots that process a whopping (but conservatively estimated) petabyte an hour. Felicity, who hacks into government databases on a whim. Felicity, who does all the geeky things, while wearing cute dresses and pink lipstick. Once these qualifications are laid out, we only have one major question left. What in the heck was Felicity doing in IT?? IT is a good, well paid job, except when you compare IT wages to Fortune-500-CEO wages or brilliant-engineers-with-lots-of-patents wages. Felicity, based on this analysis, is capable of both those things. She must be the single most underappreciated employee in the history of the universe. Get out of the basement, girl! Go start a highly lucrative, life-saving company of your own, and don’t let Oliver Queen’s moodiness get you down!
Janette Rounds is a computer-scientist-in-training who enjoys overthinking everything from cilantro proportions in salsa to faster-than-light travel.
The problem is what medium are the nanobots in? It would have to be a Cronenbergian/del Toro semi organic tech to work. A Dell workstation just doesn’t cut it. I don’t see that sort design aesthetic working in Arrow.
Does take the term of “expandability” to new heights though!
Yep. The math checks out. (Says the English teacher with no idea what she’s talking about.)
I will say that I recently binge-watched Arrow, too, and the second season is significantly better than the first, I think because it really owns its ridiculous comic bookishness. But you might want to avoid the episode where Felicity cyber-fights the Clock King because she’s worried she’s not good enough to be on the Arrow team.
“Just a heads up: normal computers don’t work like that. If we took the first derivative of a normal processor’s speed, our answer would be 0 because the derivative of any constant number is 0.”
Except that isn’t true. It’s pretty common these days for CPUs to throttle up and down the processing speed for power/thermal reasons. Furthermore, some chips can be overclocked by the end user to run faster than the officially listed maximum speed by the end user.
Great overthinking, but you need to think one more step… what if Felicity is just a common IT nerd? What if the standard IT job involves crafting rafts of nanobots and ever changing processing speed computers…
What does this say about the state of IT in the Arrow universe?
First off, loved the article. I’m a sucker for any technological deconstruction in media. Thanks for writing it. That said…
“What could be making processors?”
Why make them? Felicity hacks into city, government, business, etc. computer networks every episode. Perhaps she’s setup a botnet across Starling City and Queen Consolidated. Her processing speed increases as she distributes that data across her network, much like SETI@Home searches through radio signals. She’s not scaling up, she’s scaling out.